Databases design is going through a great deal of planning to achieve optimal storage and performance while generating the desired context for the data stored in the database tables.
Designing of a relational databases in this manner is called normalization. During the process of normalization the databases schema designer is thinking about data that is important to that business and how best fit that into data tables. They are looking for the places where data will repeat and what values depend on one another.So they can group things together logically.
Think for instance this very simple spreadsheet.
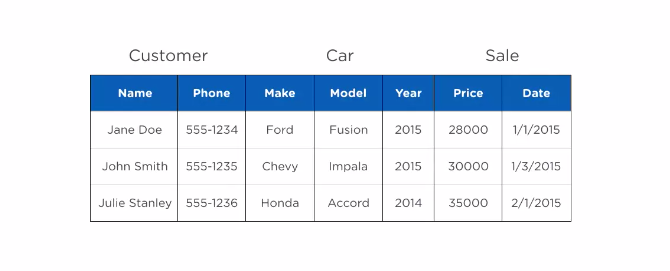
Everything is together in one large table or data set. It is easy for the humans to read like this but as you add more rows or columns it would get more and more difficult to read and maintain.
Let’s briefly look at it through the eyes of the database designer.

The database designers would probably notice that there are three main data groups:
-Customer;
-Car;
-Sale;
They would be broken apart into separate tables. They might also notice that within car there is a chance to have repeating Makes. So, they would make that separate as well.
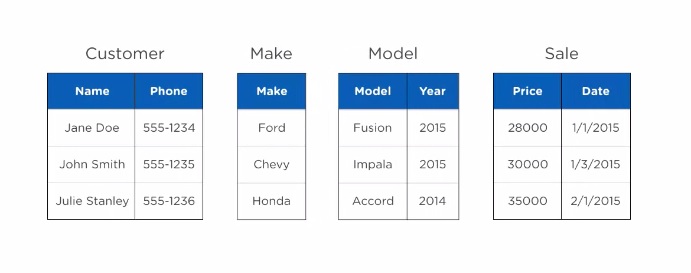
This separation is called NORMALIZATION.
As the normalization process comes to completion the designer will end with the data model that might look something like this..
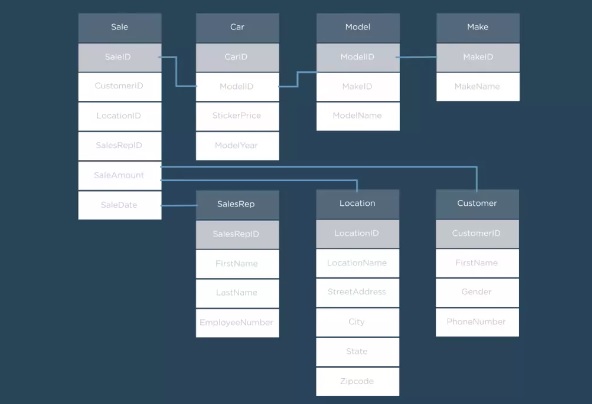
This is a crude representation of the normalization process. We will go into this a little more detail in the next post.